“Measuring programming progress by lines of code is like measuring aircraft building progress by weight.”― Bill Gates
After working for several weeks on our WikiRating:Google Summer of Code project Davide, Alessandro and I have slowly reached up to the level where we can now visualize the entire project in its final stages. It has been quite long since we wrote something , so after seeing this :

We knew it was the time that we summarize what we were busy doing in these 50 commits.
I hope you have already understood our vision by reading the previous blog post. So after a fair amount of planning it was the time that I start coding the actual engine, or more importantly start working on the <3 of the project. This was the time when my brain was buzzing with numerous Design patterns and Coding paradigms and I was finding it a bit overwhelming. I knew it was a difficult phase but I needed some force (read perseverance) to get over it. I planned , re-planned but eventually with the soothing advice of my mentors : Don’t worry about the minor intricacies now, focus on the easiest thing first. I began to code!
How stuff works?
I understand that there are numerous things to talk about and it’s easy to lose track of main theme therefore we are going to tour the engine as it actually functions that is we will see what all happen under the hood as we run the engine.Let me make it easier for you, have a look at this:
 The main method for engine run
The main method for engine run
You can see there are some methods and some parent classes involved in the main run of the engine let’s inspect them.
Fetching data(Online):
The initial step is to create all the classes for the database to store data. After this we will fetch the required data like Pages,Users and Revisions via the queries listed here.
{ “batchcomplete”: “”, “limits”: { “allpages”: 500 }, “query”: { “allpages”: [ { “pageid”: 148, “ns”: 0, “title”: “About WikiToLearn” }, { “pageid”: 638, “ns”: 0, “title”: “An Introduction to Number Theory” }, { “pageid”: 835, “ns”: 0, “title”: “An Introduction to Number Theory/Chebyshev” }, { “pageid”: 649, “ns”: 0, “title”: “An Introduction to Number Theory/Primality Tests” }, { “pageid”: 646, “ns”: 0, “title”: “An Introduction to Number Theory/What are prime numbers and how many are there?” },
This is a typical response from the Web API, giving us info about the pages on the platform.
Similarly we fetch all the other components (Users and Revisions) and simultaneous store them too.
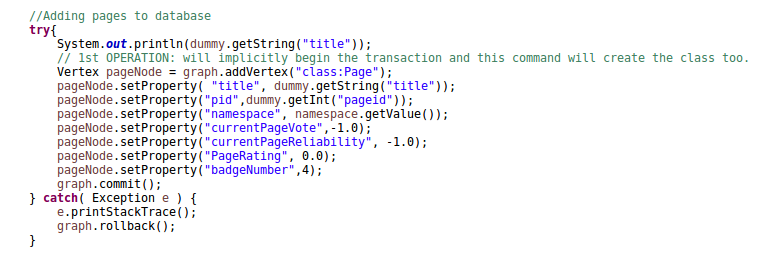 Code showing construction of Page Nodes
Code showing construction of Page Nodes
After fetching the data for Pages and Users we will work towards linking the user contributions with their corresponding user contributors . Here we will make edges from the user nodes to the respective revisions of the pages. These edges also contain useful information like the size of the contribution done.
We also need to work on linking the pages with other pages via Backlinks for calculating the PageRank (We will discuss these concepts after a short while).
Once we have all the data via the online API calls , we will now move toward our next pursuit to do offline computation on data fetched.
Computation(Offline):
Since this feature is new to WikiToLearn platform therefore there were no initial user votes on any of the page versions, hence we wrote a class to select random users and then making them vote for various pages. Later we will write a MediaWiki Extension to gather actual votes from the users but till then now we have sample data to perform further computations.
So after generating votes we need to calculate various parameters like User Credibility, Ratings, PageRank and Badges (Platinum,Gold,Silver,Bronze,Stone). The calculation of the credibility and Ratings are listed here. But Badges and PageRank are a new concept .
Badges:
We will be displaying various badges based on the Percentile Analysis of the Page Ratings. That is we will be laying the threshold for various badges say top 10% for platinum badge then we filter out the top 10% pages on the basis of their page rating and then assign them the suitable badge.The badges will give readers an immediate visual sense of the quality of the pages.
Another very important concepts are PageRank and Backlinks let’s talk about them too.
PageRank & Backlinks:
Let’s consider a scenerio :
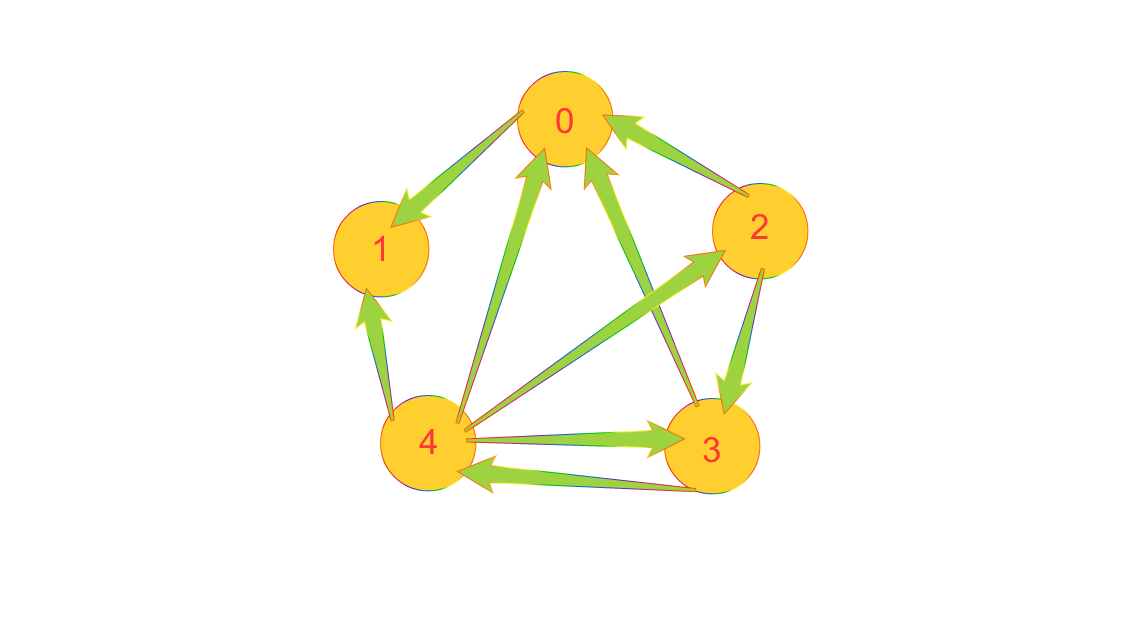 Page interconnections
Page interconnections
There are 5 pages in the system the arrows denote the hyperlink from a page to another these are called backlinks . Whenever the author decides to cite another user’s work a backlink is formed from that page to the other. It’s clear to understand that the more backlinks a page will have the more reliable it becomes (Since each time the authors decide to link someone else’s work then they actually think it is of good quality).
So the current graph :
To<From Page 0 : 4, 3, 2 Page 1 : 0 ,4 Page 2 : 4 Page 3 : 4, 2 Page 4 : 3
Here we have connections like Page 0 is pointed by 3 pages 4,3,2 and so on.
Now we will calculate a base rating of all the pages with respect to the page having maximum number of backlinks.Therefore we see that Page 0 has maximum number of backlinks(3). Then we divide the backlinks of all the other pages by the maximum.This will give us the importance of pages based on their backlinks.
We used this equation: Base Weight=(no of backlinks)/(Max backlinks)
So Base Weight of Page 0 = (1+1+1)/3=1
Here: Base weights 1, 0.666667 ,0.333333 ,0.666667 ,0.333333 of Page 0 ,Page 1 and so on
There is a slight problem here: Let’s assume that we have 3 pages A , B and C. A has high backlinks than B but according to the above computation whenever a link from A to C is there it will be equivalent to that of B to C. But it shouldn’t happen as Page A’s link carries more importance than Page B’s link because A has higher backlinks than B.Therefore we need a way to make our computation do this.
We can actually fix this problem by running the computation one more time but now instead of taking 1.0 for an incoming link we take the Base Weight so now the more important pages contribute more automatically. So the refined weights are:
Revised Base Weight of Page 0 =(0.334+0.667+0.334)/3=0.444444
Page weights 0.444444, 0.444444 ,0.111111, 0.222222 ,0.222222
So we see that the anomaly is resolved :)
This completes our engine analysis. And finally our graph in OrientDB looks like this:
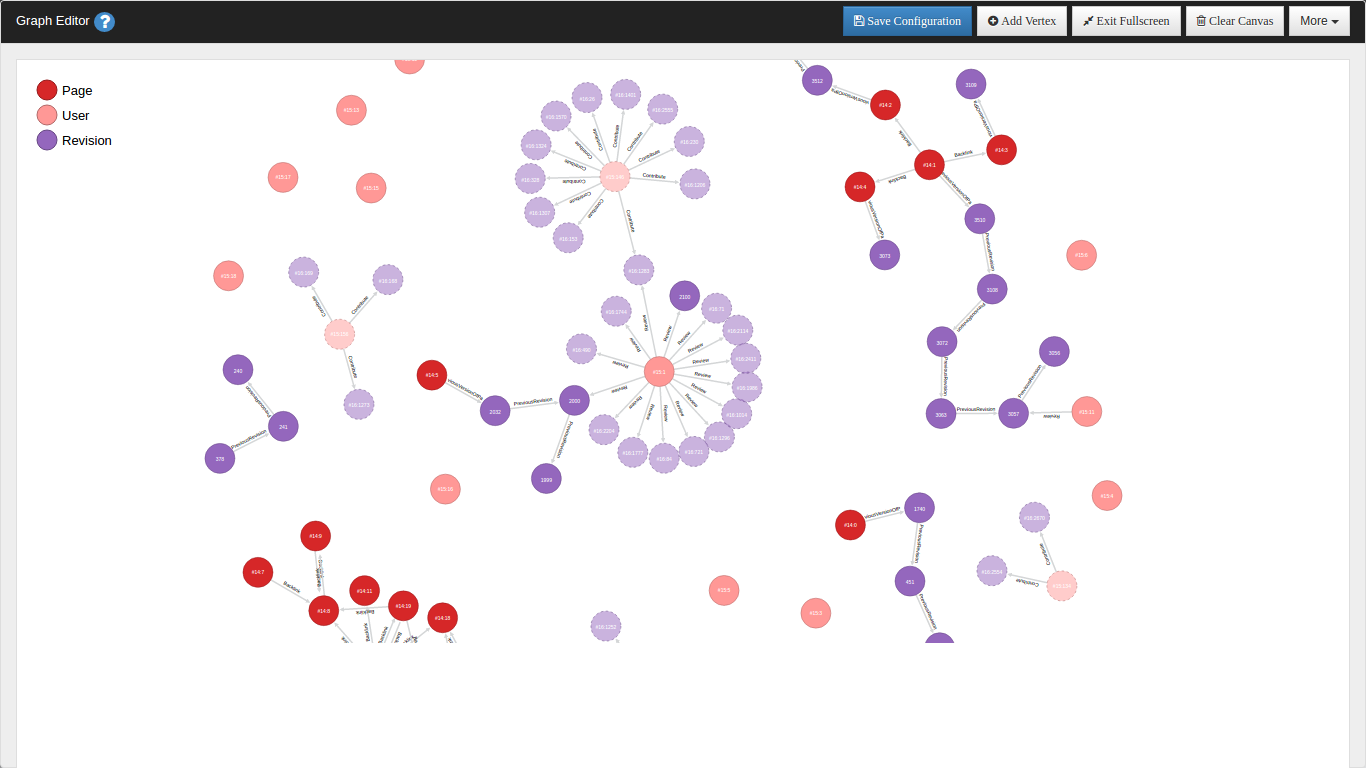
Right now I am developing an extension for the user interaction of the engine and will return soon with the latest updates. Till then stay tuned :D